


What is Delta Lake? How does it work?
Dive into the inner workings of Delta Lake, from ACID transactions to time travel, and see how it combines the best of data warehouses and data lakes.

This blog was written as part of our ongoing series of reading Delta, IceBerg, and Hudi white papers. I hold a lively Q&A session where participants ask insightful questions about any data topic. For privacy concerns, I do not publish the Q&A section of the meeting.
To join the next session follow me on LinkedIn or join Discord. It's an excellent opportunity to learn, ask questions, and connect with community members.
Video Recording Of The Session
1. What is Delta Lake?
Delta Lake (or Delta Table) represents a significant evolution in data storage technology, designed to bring reliability and robustness to data lakes. As an open-source storage layer, it introduces ACID transactions to cloud object stores like Amazon S3, addressing critical challenges that have long plagued traditional data lakes. These challenges include data corruption, consistency issues, and performance problems that have hindered the effectiveness of big data analytics.
By providing a unified data management layer, Delta Lake bridges the gap between traditional data warehouses and modern data lakes, offering the best of both worlds: the scalability and flexibility of data lakes with the reliability and performance of data warehouses.
2. The Core of Delta Lake: The Transaction Log
At the heart of Delta Lake's functionality lies the transaction log. This crucial component is stored in a "_delta_log" subdirectory within the table's location. The log consists of two main elements:
JSON files: These are numbered sequentially (e.g., 00000.json, 00001.json) and represent individual atomic commits.
Parquet checkpoints: These provide efficient snapshots of the table state at specific points in time.
Each JSON file in the transaction log contains actions that describe changes made to the table. These actions can include:
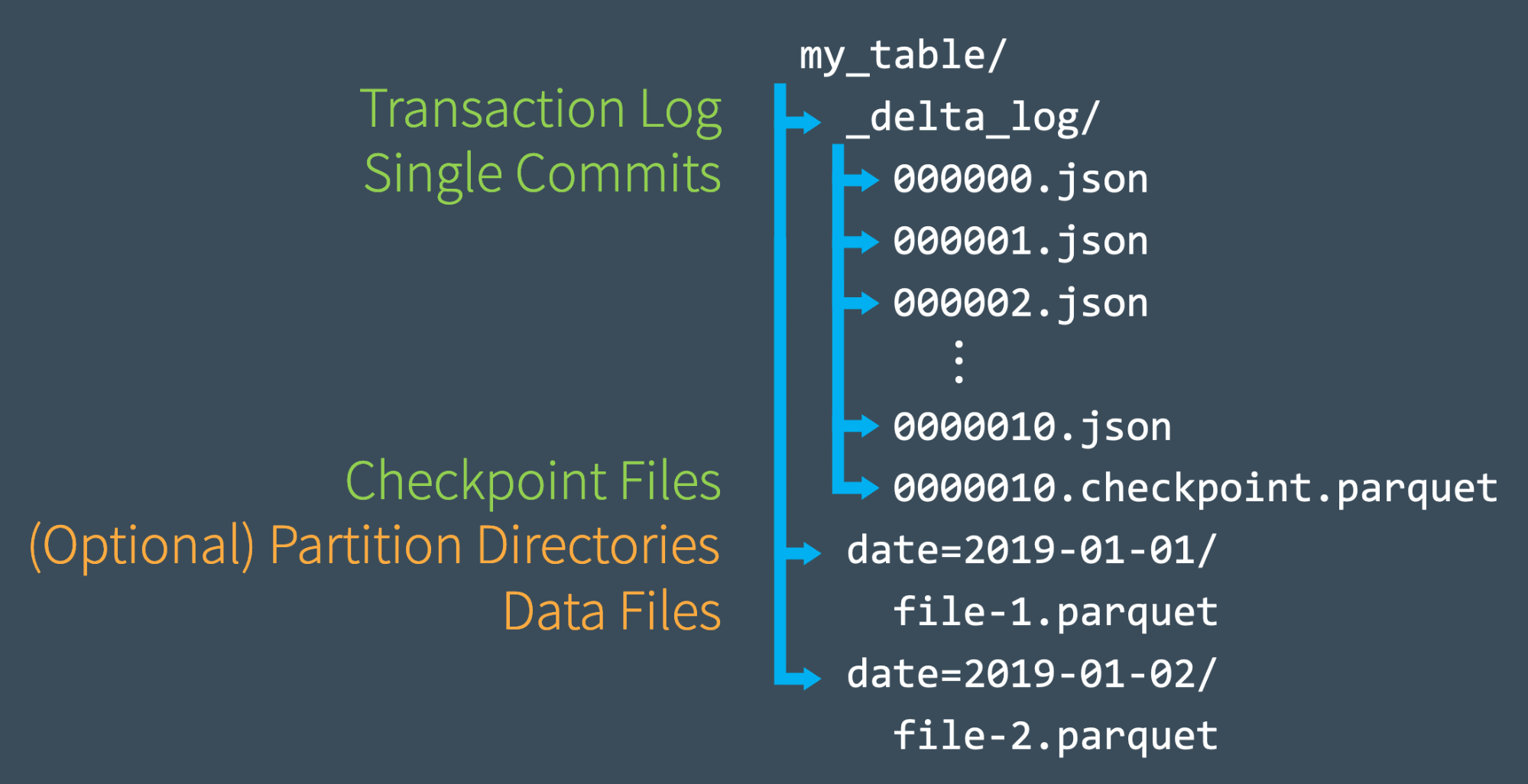
Inside the Delta Log
Add file actions: Indicates files committed to the table, including statistics
Remove file actions: Used for logical deletion of files
Update metadata - Updates the table’s metadata (e.g., changing the table’s name, schema or partitioning).
Set transaction - Records that a structured streaming job has committed a micro-batch with the given ID.
Change protocol - enables new features by switching the Delta Lake transaction log to the newest software protocol.
Commit info - Contains information around the commit, which operation was made, from where and at what time.
The transaction log serves as the single source of truth for the table's state, enabling Delta Lake to provide its key features and guarantees. Those actions are then recorded in the transaction log as ordered, atomic units known as commits.
3. Write-Ahead Logging and Optimistic Concurrency Control in Delta Lake
Write-Ahead Logging (WAL)
Write-Ahead Logging is a crucial mechanism in Delta Lake that ensures data integrity and enables ACID transactions. Key aspects of WAL include:
Before any changes are made to the data files, Delta Lake writes the details of the transaction to the transaction log.
The log is stored in the "_delta_log" subdirectory and contains JSON files describing all operations, including file additions and removals.
Each JSON file represents a new version of the table and is updated atomically for every operation.
WAL ensures atomicity and durability of transactions.
If a system failure occurs, the log contains sufficient information to either complete the transaction during recovery or roll it back, preventing partial updates.
Optimistic Concurrency Control
Optimistic Concurrency Control (OCC) is a method used in database management systems and other distributed systems to handle concurrent access to shared resources. In the context of Delta Lake, OCC is employed to manage multiple writers without locking the entire table.
Allows for high concurrency, which is particularly effective for big data workloads where appends are more common than updates to existing records.
Enables writers to perform operations without acquiring locks, improving performance in scenarios with low conflict rates.
Involves checking for conflicts only at the time of commit, rather than throughout the entire transaction.
Relationship between WAL and Optimistic Concurrency Control
WAL and optimistic concurrency control work together in Delta Lake to provide ACID transactions while maintaining high performance and concurrency. Their relationship functions as follows:
When a writer starts a transaction, it records the start version of the table from the transaction log.
The writer performs its operations and attempts to commit by creating the next numbered JSON file in the transaction log.
If another writer has committed in the meantime, it checks for conflicts by examining the changes in the log since its read version.
If there are no conflicts (e.g., both were appends), it can still commit without rewriting files or redoing computations.
In case of conflicts, the transaction fails and can be retried.
This synergy between WAL and optimistic concurrency control allows Delta Lake to provide robust transaction management while optimizing for the high-concurrency, append-heavy workloads common in big data environments.
4. Ensuring ACID Transactions on a Data Lake
Delta Lake's implementation of ACID properties is central to its functionality. Here's how each property is achieved:
Atomicity
Delta Lake achieves atomicity through write-ahead logging. Before executing any changes to the data files, it writes the details of the transaction to the transaction log. atomicity, guarantees that operations (like an INSERT or UPDATE) performed on your data lake either complete fully, or don’t complete at all. Without this property, it’s far too easy for a hardware failure or a software bug to cause data to be only partially written to a table, resulting in messy or corrupted data.
The transaction log is the mechanism through which Delta Lake is able to offer the guarantee of atomicity. For all intents and purposes, if it’s not recorded in the transaction log, it never happened. By only recording transactions that execute fully and completely, and using that record as the single source of truth, the Delta Lake transaction log allows users to reason about their data, and have peace of mind about its fundamental trustworthiness, at petabyte scale.
Consistency
Consistency in Delta Lake is maintained through two primary mechanisms:
Schema Enforcement: Delta Lake automatically checks that incoming data adheres to the table's schema, as defined in the transaction log metadata. If a transaction tries to insert data that doesn't comply with the current schema, it is rejected.
Invariant Checking: Any user-defined invariants (like NOT NULL constraints) are enforced before committing the transaction. If these invariants are violated, the transaction is aborted.
Isolation
Delta Lake provides snapshot isolation, which protects reading transactions from ongoing modifications. This is achieved as follows:
When a read transaction starts, it points to a specific version of the data, which corresponds to a state of the transaction log.
Subsequent modifications (writes) do not affect this version, ensuring that the read transaction sees a consistent and unchanging view of the data, even as other modifications proceed.
Durability
Durability in Delta Lake is ensured through immediate recording of committed transactions:
As soon as a transaction is committed, it is recorded in the transaction log.
The log is typically flushed to persistent storage immediately.
This approach ensures that the transaction's effects persist across system failures.
The recovery process uses the log to reapply committed transactions that might not have been written to the data files before a failure.
5. Efficient Data Reading and Performance Optimizations
Delta Lake employs a sophisticated process to read data efficiently, which is crucial for maintaining performance with large datasets:
It finds the latest checkpoint file and reads subsequent JSON log files.
File statistics stored in the log are used to prune irrelevant data files, reducing the amount of data that needs to be processed.
Delta Lake leverages Spark to parallelize the reading of log files and data, further enhancing performance.
Performance Optimizations
Delta Lake incorporates several performance optimizations to enhance query efficiency and data management:
Data Skipping: Utilizes statistics in the transaction log to skip irrelevant files during queries, significantly reducing query time.
Compaction: Combines small files into larger ones to improve read performance and reduce metadata overhead.
Vacuum: Removes old files no longer needed for time travel or snapshot isolation, helping to manage storage costs.
Z-Ordering: Optimizes the physical layout of the data to colocate related information, improving query efficiency by reducing the amount of data that needs to be read.
6. Time Travel and Rollbacks
One of Delta Lake's standout features is its support for time travel capabilities. This feature is made possible by the multi-version transaction log. Users can query previous versions of the table using:
Version numbers
Timestamps
Time travel is particularly useful for:
Undoing errors in data pipelines
Reproducing old versions of data for auditing or compliance purposes
Comparing data across different points in time
7. Additional Features
Delta Lake offers several additional features that enhance its functionality and usability:
UPSERT, DELETE, and MERGE operations: These operations allow for efficient data updates without the need for full table rewrites.
Schema evolution: Delta Lake supports adding, deleting, and modifying columns, enabling tables to adapt to changing data requirements.
Schema enforcement: This feature ensures that all data written to a table conforms to the table's schema, preventing data quality issues.
Audit logging: The transaction log serves as a built-in audit log, tracking all changes made to the table over time.
8. Recent Improvements in Delta Lake
Delta Lake continues to evolve, with recent improvements including:
Support for Iceberg Compatibility V2: This ensures Delta tables can be converted to Apache Iceberg™ format, enhancing interoperability between different data lake technologies.
Introduction of Row Tracking: Row tracking is a feature in Delta Lake that allows for tracking rows across multiple versions of a Delta table. It exposes two metadata columns:
Row IDs: These are unique identifiers for each row in the table.
Row Commit Versions: These indicate the version of the table when each row was last modified.
This feature enhances data lineage capabilities, allowing users to track changes to individual rows over time. It's particularly useful for auditing, compliance, and understanding data evolution within a Delta table.
Addition of the V2 Checkpoint Table Feature: This introduces support for V2 Checkpoints, allowing for more efficient checkpoint management and potentially improving read performance.
Introduction of Timestamp without timezone (TimestampNtz) data type: This new data type provides support for timestamps without timezone information, offering more flexibility in handling time-based data.
Deletion Vectors: Deletion vectors are a powerful feature in Delta Lake that optimize the handling of row-level deletions in tables. Instead of rewriting entire data files when rows are deleted, deletion vectors store information about which rows have been invalidated or "soft deleted". This approach significantly improves the performance of delete operations, especially for large datasets. Deletion vectors are stored in binary format in the root directory of the table alongside data files, and each deletion vector can contain information for multiple data files. By enabling "soft deletes", deletion vectors provide a more efficient alternative to physically removing data. This mechanism not only enhances delete operation performance but also supports time travel capabilities, allowing users to query previous versions of the table even after deletions have occurred. The use of deletion vectors exemplifies Delta Lake's commitment to optimizing data management operations while maintaining transactional integrity and historical data accessibility.8. Limitations and Best Practices
9. When not to use Delta
Not recommended for OLTP workloads: Delta Lake is better suited for OLAP and big data use cases rather than high-frequency, low-latency transaction processing.
Time travel limitations: While a powerful feature, maintaining historical versions for extended periods can become costly in terms of storage.
Transaction rate limitations: High-frequency transactions are limited by the latency of put-if-absent operations on cloud object stores, which can be in the range of tens to hundreds of milliseconds.
Conclusion
Delta Lake has not only merged the scalability of data lakes with the robustness of data warehouses, but it has also established itself as the predominant storage format of choice within the lakehouse paradigm. By continuously evolving to include features like row tracking, schema evolution, and advanced concurrency controls, Delta Lake addresses the dynamic and growing needs of modern data architectures. Its sophisticated transaction log system, combined with ACID compliance and performance optimizations, ensures data integrity and query efficiency at scale. As the landscape of big data management and analytics continues to evolve, Delta Lake is poised to play a crucial role, offering organizations enhanced data reliability, improved performance, and greater flexibility in managing large-scale datasets.
Reference
Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores
Diving Into Delta Lake: Unpacking The Transaction Log