


Kafka Explained: Key Concepts and Architecture Principles
Learn the fundamentals of Kafka, including its architecture, core components, and how it handles real-time data processing with high throughput.

1. Introduction to Kafka
Kafka was created to address the challenges of processing large volumes of log data, which is vital for analytics, monitoring user activity, system metrics, and more. Unlike traditional messaging systems, Kafka is designed to provide high throughput, scalability, and durability. It supports both offline and online message consumption, making it versatile for various use cases. It is primarily written in Java but provides many ways to interact with it using tooling and wrappers built around it.
2. Core Components of Kafka
Kafka's architecture is built around the following core components:
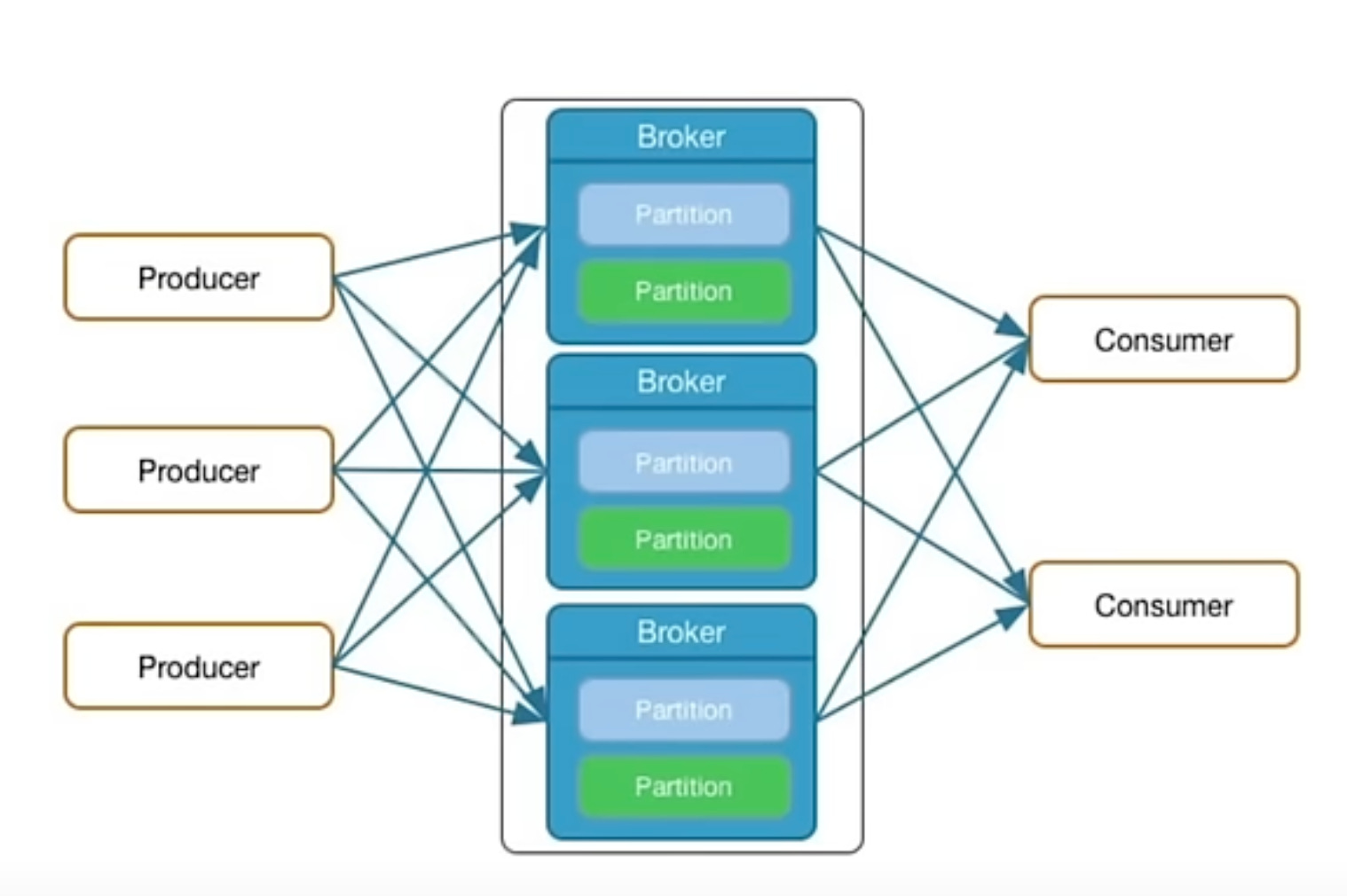
Topics: A stream of messages belonging to a particular category is defined by a topic. Producers publish messages to topics, and consumers subscribe to topics to consume the messages. Topics could be thought as analogous to tables in a database world.
Producers: These are the processes that publish messages to Kafka topics. Producers push data to Kafka brokers, which are responsible for storing and managing the data.
Brokers: These are the physical machines/hosts/nodes/servers which have Kafka deployed on them. Kafka brokers are servers that store published messages and serve them to consumers. Kafka is distributed, meaning a Kafka cluster typically consists of multiple brokers to handle large-scale data.
Consumers: Consumers subscribe to one or more topics and process the stream of records produced to those topics. They pull data from brokers at their own pace.
Partitions: Each topic in Kafka is split into partitions, which are the unit of parallelism within Kafka. Each partition is an ordered, immutable sequence of records that is continually appended to. Kafka distributes data across multiple brokers using these partitions.
Consumer Groups: Kafka allows multiple consumers to read data from a topic simultaneously by using consumer groups. Each consumer in a group reads from a different partition, allowing parallel processing.
2.1 Understanding the relationships: Topics, Partitions and Segments
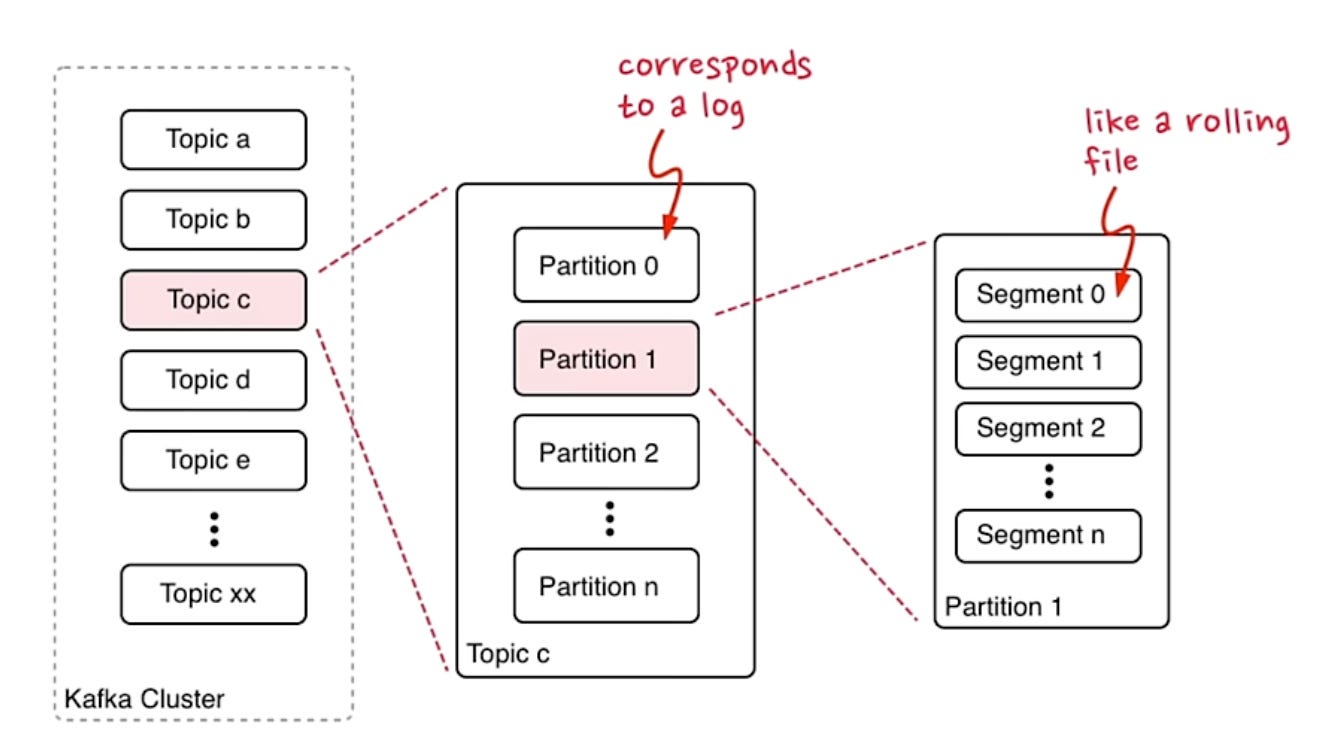
When you create a topic you get to choose how many partitions you want.
You can have unlimited topics
Messages are unordered across partitions but ordered within them.
Kafka cluster does not monitor the size of the partitions if one is getting too over loaded. While Kafka does not automatically balance the size of partitions based on their size or data volume, it does provide tools like Cruise Control for monitoring and balancing partition load across brokers. Also, users can manually configure and manage partitions to avoid any single partition becoming a bottleneck.
Logs are immutable, we set retention period so things drop off from the log.
Every partition in Kafka has its own unique offset space, but an offset number alone does not identify which partition contains the message. To locate a specific message, you need both the partition number and the offset within that partition.
3. What does a message look like?
A Kafka message, also known as a record, consists of a key, value, timestamp, and optional headers. Here's a breakdown of what each component of a Kafka message typically includes:
Key: An optional piece of data used to partition messages within Kafka topics. It helps determine which partition the message will be written to. If a key is provided, Kafka uses a hash of the key to assign the message to a specific partition. If no key is provided, messages are distributed round-robin across partitions.
Value: The main data or payload of the message. This is the actual information being sent through Kafka, which could be in any format, such as a string, JSON, Avro, etc.
Timestamp: Automatically generated by Kafka, it represents the time the message was produced or written to the Kafka topic. This can be used for various purposes, such as ordering messages or calculating the message's age.
Headers: An optional key-value pair that can carry additional metadata about the message. Headers are used to include extra information that may not be part of the message payload.
Note: Kafka guarantees at least once delivery so down streams need to handle the possibility of the same message arriving more than once.
Example of a Kafka Message in JSON format
Here’s a simple example of what a Kafka message might look like in JSON format:
{
"key": "user123",
"value": {
"name": "Alice",
"action": "login",
"timestamp": "2024-08-24T12:00:00Z"
},
"headers": {
"source": "web",
"user-agent": "Mozilla/5.0"
}
}3.1 Relationship between Consumer & Consumer Group
They can pull messages from multiple topics or a single topic
Consumer/Client Application ideally needs to remember what offset do they want to read messages from
A consumer group is a set of consumers that work together to consume messages from one or more Kafka topics.
Kafka now remember what the consumer last consumed which is stored as another topic called “consumer offsets’. One can find this information from Kafka CLI.
Each new application which talks to Kafka gets assigned a consumer group. For Kafka to recognize that many apps are trying to share the same workload they need to have the same consumer group
Max number of consumers = 2 x (Total Number of Partitions assigned to the topic). For Kinesis, Max number of consumers = Total Number of Partitions assigned to the topic
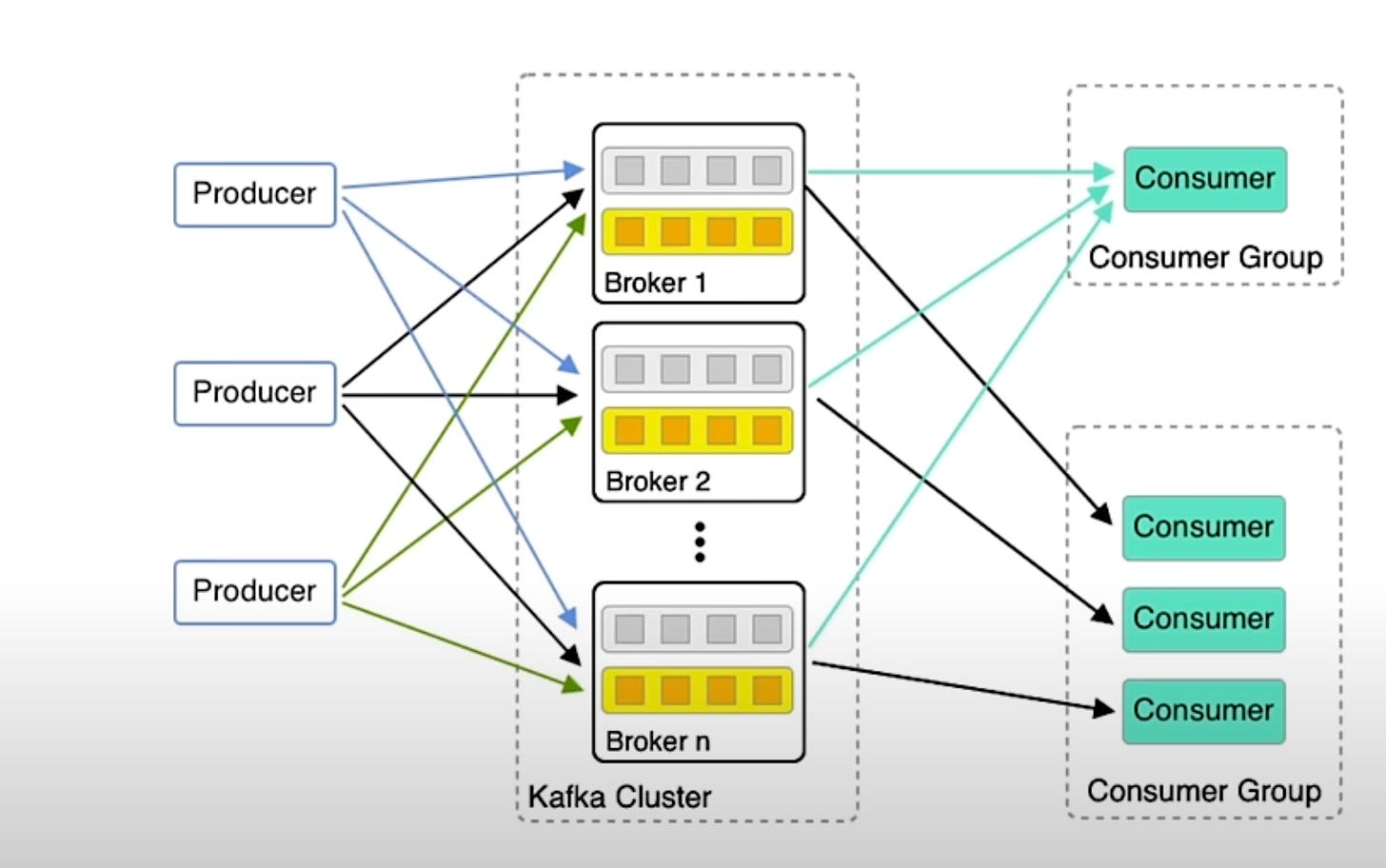
Image courtesy of Confluent.
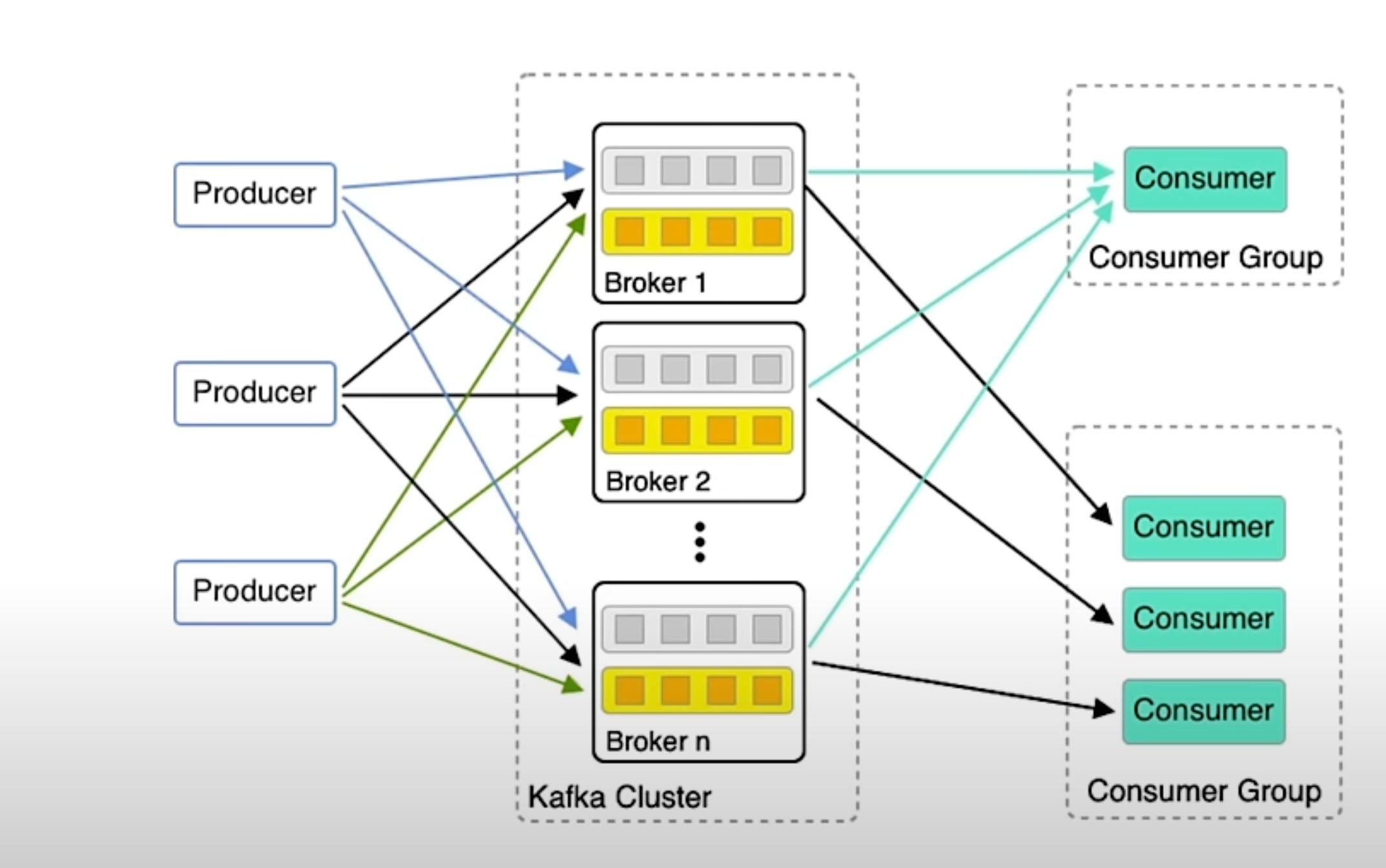
Multiple Consumer Groups: You can have multiple consumer groups reading from the same topic. Each group maintains its own set of offsets, allowing different applications to process the same data independently at different speeds or with different logic.
Consumer Group Coordination: Kafka's
group coordinatorandconsumer coordinatormanage consumer groups. When a consumer joins or leaves a group, Kafka's coordinator orchestrates the rebalance of partitions among the active consumers.Rebalancing: When a consumer joins or leaves, Kafka triggers a rebalance to distribute partitions among the consumers, which may cause a temporary halt in message consumption.
Group ID: The
group.idis essential for identifying the consumer group and managing offsets. Different applications or microservices should use different group IDs to consume data independently.
4. Kafka's Architecture Design Principles
Kafka's design is guided by several principles aimed at maximizing efficiency and scalability:
4.1 Log-Based Storage
Kafka uses a log-based storage mechanism, where each partition is a sequential log of records. This approach ensures that read and write operations are fast because data is only appended to the log, minimizing disk seek time. Kafka does not maintain any state for messages consumed by consumers, reducing the complexity of broker operations.
4.2 Distributed System Coordination
Kafka is a distributed system that uses Apache Zookeeper to manage its coordination. Zookeeper handles various tasks like tracking brokers, maintaining partition metadata, and facilitating leader election among Kafka brokers to ensure high availability and fault tolerance.
4.3 High Throughput and Low Latency
Kafka is optimized for high throughput and low latency. It achieves this through efficient batching of messages, reducing network overhead, and leveraging file system caches. Kafka also uses a "pull" model for consumers, allowing them to fetch messages at their own pace and avoid being overwhelmed by the brokers.
5. What makes Kafka Durable?
Broker replication in Kafka is a fundamental mechanism that ensures both durability and high availability of data within the Kafka cluster. When a topic is created in Kafka, it is divided into partitions, and each partition is replicated across multiple brokers according to the specified replication factor. For instance, if a topic has a replication factor of 3, each partition will have three replicas: one on the leader broker and two on follower brokers.
The leader broker is responsible for handling all the read and write requests for a particular partition. Meanwhile, follower brokers replicate the data from the leader to maintain identical copies of the partition log. This replication is achieved by continuously fetching the latest messages from the leader and writing them to their own logs, in the exact same order as the leader.
6. Conclusion
Kafka's architecture is a testament to its design philosophy of simplicity, scalability, and efficiency. By combining the best aspects of messaging systems and log aggregators, Kafka has established itself as a powerful tool for real-time data processing and analytics. As the need for fast, reliable data pipelines continues to grow, Kafka's role in the ecosystem is poised to expand further.\
Lets take a short Quiz to validate our understanding
Watch Our Session Readout
We're excited to share the recording of our recent session where we read and discussed key papers on Kafka, Spark, and Spark Streaming. This session is part of our ongoing series aimed at deepening our understanding of these powerful technologies through collaborative reading and discussion.
After the readout, we hold a lively Q&A session where participants asked insightful questions about any data topic.
If you're interested in joining us for future sessions, where we explore more papers on Kafka, Spark, Spark Streaming, and other cutting-edge technologies, you can register here. It's a great opportunity to learn, ask questions, and connect with others in the community!
Video Recording Of The Session
Stay tuned
Next week's blog post, where we'll dive deeper into the best practices for running Kafka effectively. We will cover topics like optimizing performance, easy scaling, and more. Don't miss it!