


Ensuring Data Quality in the Hybrid World of Streaming and Scheduled ETL
How to Schedule Downstream ETL Jobs When Upstream Is a Streaming Job

Introduction
In modern data architectures, it's increasingly common to have upstream data pipelines ingesting data continuously through streaming processes, while downstream systems rely on scheduled Extract, Transform, Load (ETL) jobs to process and analyze this data. Coordinating these two paradigms—streaming ingestion and scheduled batch processing—poses a significant challenge. The critical question is:
How do you decide when to run downstream ETL jobs when the upstream data is continuously streaming in?
This article explores various strategies to address this challenge, ensuring data consistency, accuracy, and timeliness in your downstream processes. We will delve into methods involving observable metrics, buffer-based scheduling, dbt (Data Build Tool) data quality checks, and more, providing practical guidance for data engineers and architects.
The Challenge
The primary difficulty lies in synchronizing the downstream ETL jobs with the upstream streaming data. Without proper coordination, downstream jobs might start processing incomplete or inconsistent data, leading to inaccurate results, data quality issues, or even system failures. The goal is to determine an optimal time or condition under which the downstream ETL jobs can safely execute, knowing that they have all the necessary data from the upstream streaming source.
Observable Metrics in Structured Streaming
Monitoring the health and progress of your streaming applications is crucial for making informed decisions regarding downstream ETL processes. Apache Spark Structured Streaming, commonly used in platforms like Databricks, provides observable metrics that can be leveraged for this purpose. These metrics vary based on the source of the streaming data:
1. Kafka Metrics
When using Apache Kafka as the source, you can monitor the following metrics:
avgOffsetsBehindLatest: The average number of offsets that the streaming query is behind the latest available offset across all subscribed topics.maxOffsetsBehindLatest: The maximum number of offsets that the streaming query is behind the latest available offset across all subscribed topics.minOffsetsBehindLatest: The minimum number of offsets that the streaming query is behind the latest available offset across all subscribed topics.estimatedTotalBytesBehindLatest: The estimated total number of bytes that the streaming query has yet to consume from the subscribed topics.
2. Delta Lake Metrics
For Delta Lake as the streaming source, the relevant metrics include:
numInputRows: The number of rows read in each micro-batch.inputRowsPerSecond: The rate at which data is being ingested.processedRowsPerSecond: The rate at which data is being processed.batchId: The unique identifier for each micro-batch, which can be useful for tracking progress.
3. Kinesis Metrics
When using Amazon Kinesis as the source, important metrics are:
avgMsBehindLatest: The average number of milliseconds the consumer is behind the latest data in the stream.maxMsBehindLatest: The maximum number of milliseconds the consumer is behind the latest data.minMsBehindLatest: The minimum number of milliseconds the consumer is behind the latest data.totalPrefetchedBytes: The total number of bytes prefetched but not yet processed, indicating the backlog.
These metrics help you understand the lag in your streaming job and make informed decisions about when the downstream ETL jobs should run.
Decision Flow
To visualize the flow and interactions between the upstream streaming job and downstream ETL processes, here is a Mermaid diagram:
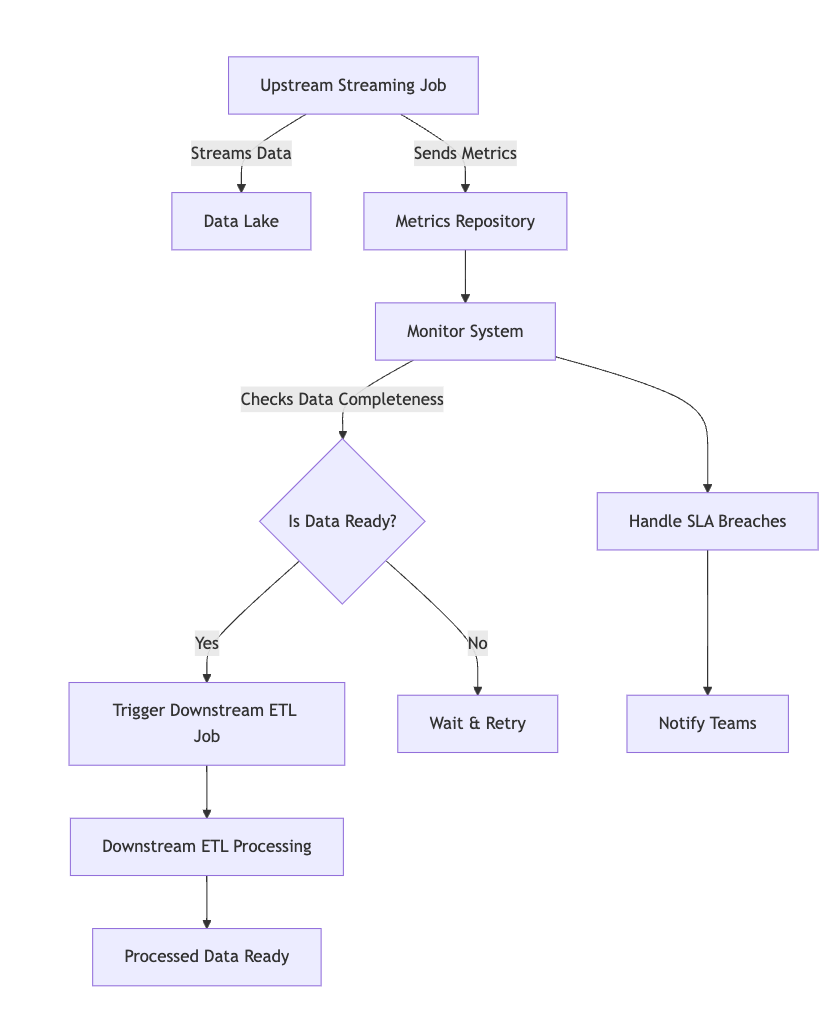
Explanation:
The Upstream Streaming Job writes data continuously to the Data Lake, typically in Delta tables.
It also writes metrics to a Metrics Table, which is used to monitor the streaming job's progress.
A Data Completeness Check is performed by querying the Metrics Table.
If the lag is within acceptable thresholds, it Triggers the Downstream ETL Job.
If the lag exceeds thresholds, it may Wait or Alert teams to handle the delay.
The Downstream ETL Job processes the data and produces Processed Data for consumption.
Notifications or alerts are sent to teams to Handle Delays if necessary.
Solutions
Let's explore various strategies to synchronize downstream ETL jobs with upstream streaming data.
1. Monitoring Streaming Metrics via StreamingQueryListener
Apache Spark provides the StreamingQueryListener interface, allowing you to monitor the progress and status of your streaming queries in real time. By attaching a StreamingQueryListener to your streaming job, you can access the metrics critical for determining downstream ETL execution.
Implementation Steps:
Attach a
StreamingQueryListener:
spark.streams.addListener(new StreamingQueryListener() {
override def onQueryStarted(event: QueryStartedEvent): Unit = {
// Handle query started events
}
override def onQueryProgress(event: QueryProgressEvent): Unit = {
// Extract and store metrics
val progress = event.progress
val sources = progress.sources
sources.foreach { source =>
val metrics = source.metrics
// Access metrics like avgOffsetsBehindLatest, etc.
}
}
override def onQueryTerminated(event: QueryTerminatedEvent): Unit = {
// Handle query termination
}
})
Store Metrics for Access:
Push metrics to third-party observability tools like Datadog, Prometheus, or Grafana using their respective APIs or exporters.
Write metrics to a Delta table for easy querying and dashboarding within your data lake.
Determine Acceptable Lag:
Define thresholds for acceptable lag or backlog based on your business requirements.
Downstream ETL jobs can query the stored metrics to check if the lag is within acceptable limits before starting.
Benefits:
Data Accuracy: Ensures that downstream jobs process data only when it's sufficiently up-to-date.
Flexibility: Downstream teams can define their own thresholds for data freshness.
Real-Time Monitoring: Provides up-to-date information about the streaming job's progress.
Considerations:
Complexity: Requires additional infrastructure to store and query metrics.
Maintenance Overhead: The monitoring system needs to be maintained and monitored itself.
2. Buffer-Based Scheduling with Service Level Agreements (SLAs)
In some scenarios, the upstream team can provide a Service Level Agreement (SLA) guaranteeing that the streaming job will not fall behind by more than a certain amount of time (e.g., 2 hours). Downstream teams can then schedule their ETL jobs with an additional buffer to account for any unforeseen delays.
Implementation Steps:
Establish SLAs with the Upstream Team:
Agree on maximum allowable lag times.
Document these SLAs and communicate them clearly to all stakeholders.
Schedule Downstream Jobs with a Buffer:
If the SLA is 2 hours, downstream jobs can add an additional buffer (e.g., 1 hour) and schedule their jobs to run 3 hours after data publication.
Use scheduling tools like Apache Airflow, Cron, or the scheduling features in your ETL platform.
Benefits:
Simplicity: No need for complex monitoring or coordination mechanisms.
Predictability: Downstream jobs run at fixed times, making planning easier.
Considerations:
Risk of Inaccuracy: If the upstream job falls behind beyond the SLA, downstream jobs may process incomplete data.
Lack of Real-Time Adaptation: This method doesn't account for real-time variations in data availability.
Communication: Requires strong communication and trust between upstream and downstream teams.
3. Utilizing dbt Pre-hooks for Data Completeness Checks
If you're using dbt (Data Build Tool) for your ETL processes, you can leverage pre-hooks and macros to check for data completeness before running transformations. dbt allows you to execute SQL statements before and after model runs, providing a mechanism to enforce data quality checks.
Implementation Steps:
Write Streaming Metrics to a Delta Table:
Ensure that the upstream streaming job writes its metrics to a Delta table accessible by dbt.
This table should include the relevant metrics needed to assess data completeness.
Create a dbt Macro for Completeness Checks:
-- macros/check_data_completeness.sql
{% macro check_data_completeness() %}
{% set result = run_query("SELECT avg_offsets_behind_latest FROM streaming_metrics WHERE metric_timestamp = (SELECT MAX(metric_timestamp) FROM streaming_metrics)") %}
{% set avg_offsets_behind_latest = result.columns[0][0] %}
{% if avg_offsets_behind_latest | int > 100 %}
{{ exceptions.raise_compiler_error("Data is not complete: avgOffsetsBehindLatest is too high.") }}
{% endif %}
{% endmacro %}
Implement a Pre-hook in dbt Models:
# models/model_name.yml
models:
your_project_name:
your_model_name:
pre-hook:
- "{{ check_data_completeness() }}"
Abort Execution if Data Is Incomplete:
The macro raises an exception if the data completeness check fails, preventing the model from running.
Benefits:
Automated Checks: Ensures data completeness before processing.
Integration with ETL Process: Seamlessly fits into existing dbt workflows.
Customization: You can tailor the checks to your specific needs.
Considerations:
Dependency on Upstream Metrics: Requires reliable metrics from the upstream job.
Maintenance: Additional logic that must be maintained and updated as requirements change.
dbt Environment: All team members need to be familiar with dbt's features and macros.
4. Decoupled Approach with Metrics in Delta Tables
A decentralized method involves storing all streaming metrics in a Delta table, allowing downstream teams to independently verify data completeness without direct coordination with the upstream team.
Implementation Steps:
Upstream Team Stores Metrics:
The streaming job writes metrics and statuses to a Delta table in a shared data lake.
Metrics can include data ingestion times, counts, lags, etc.
Downstream Teams Implement Custom Logic:
Query the Delta table to check if data meets their completeness criteria.
Implement checks within their ETL jobs to decide whether to proceed.
Upstream Team Communicates SLA Breaches:
Set up automated notifications (e.g., email, Slack) to alert downstream teams of any SLA breaches or significant delays.
Use monitoring tools or custom scripts to detect when metrics indicate a problem.
Benefits:
Decoupling: Minimizes dependencies between teams.
Customization: Downstream teams define their own completeness criteria.
Scalability: Works well as the number of downstream consumers grows.
Considerations:
Data Governance: Requires agreement on where and how metrics are stored.
Security and Access Control: Ensure that only authorized teams can access the metrics.
Data Consistency: All teams need to agree on the definitions of the metrics.
5. Triggering ETL Jobs via APIs
In environments like Databricks, you can use APIs to programmatically trigger downstream ETL jobs based on certain conditions. This approach enables a push-based model where the completion of upstream processing triggers downstream jobs.
Implementation Steps:
Monitor Upstream Metrics:
Use scripts or monitoring tools to watch for data completeness.
When the data is deemed complete, trigger the downstream job.
Trigger Jobs via API:
Use the Databricks REST API to start the downstream ETL job.
Automate with Webhooks or Event-Driven Architecture:
Set up webhooks or use event-driven services like AWS Lambda, Azure Functions, or Google Cloud Functions to trigger the job when conditions are met.
Benefits:
Automation: Removes the need for manual intervention.
Responsiveness: Downstream jobs start as soon as data is ready.
Flexibility: Can integrate with various monitoring and alerting systems.
Considerations:
API Management: Requires secure handling of API tokens and endpoints.
Error Handling: Need to manage cases where the job fails to start or complete.
Complexity: Increases the complexity of the orchestration layer.
6. Adding Delays for Non-Critical Use Cases
In scenarios where absolute data accuracy is not critical, a simple approach is to add a fixed delay before running downstream ETL jobs. This method assumes that the data will be sufficiently complete for the downstream processes after a certain period.
Implementation Steps:
Determine Maximum Expected Delay:
Consult with the upstream team to understand the worst-case lag times.
Schedule Jobs After the Delay:
If the upstream SLA is 2 hours, and you anticipate possible delays up to 8 hours, schedule the downstream job to run after 8 hours.
Benefits:
Simplicity: Easy to implement without additional infrastructure.
Resource Optimization: Jobs run during off-peak hours, potentially reducing costs.
Considerations:
Data Staleness: Downstream data may not be as fresh as possible.
Inefficiency: Unnecessarily long delays may affect business processes.
Assumptions: Relies on the assumption that delays will not exceed the fixed window.
Conclusion
Synchronizing scheduled downstream ETL jobs with upstream streaming data sources requires a balance between data accuracy, system complexity, and team coordination. Multiple approaches exist:
Metric Monitoring: Provides precise control but requires additional infrastructure and maintenance.
Buffer-Based Scheduling: Simplifies coordination but may risk data accuracy if upstream delays occur.
dbt Pre-hooks and Custom Logic: Offers automation and customization at the cost of added complexity and dependencies.
Decoupled Approaches: Promote team independence but require robust data governance and clear metric definitions.
API Triggering and Fixed Delays: Offer flexibility and simplicity but may introduce complexity or data staleness, respectively.
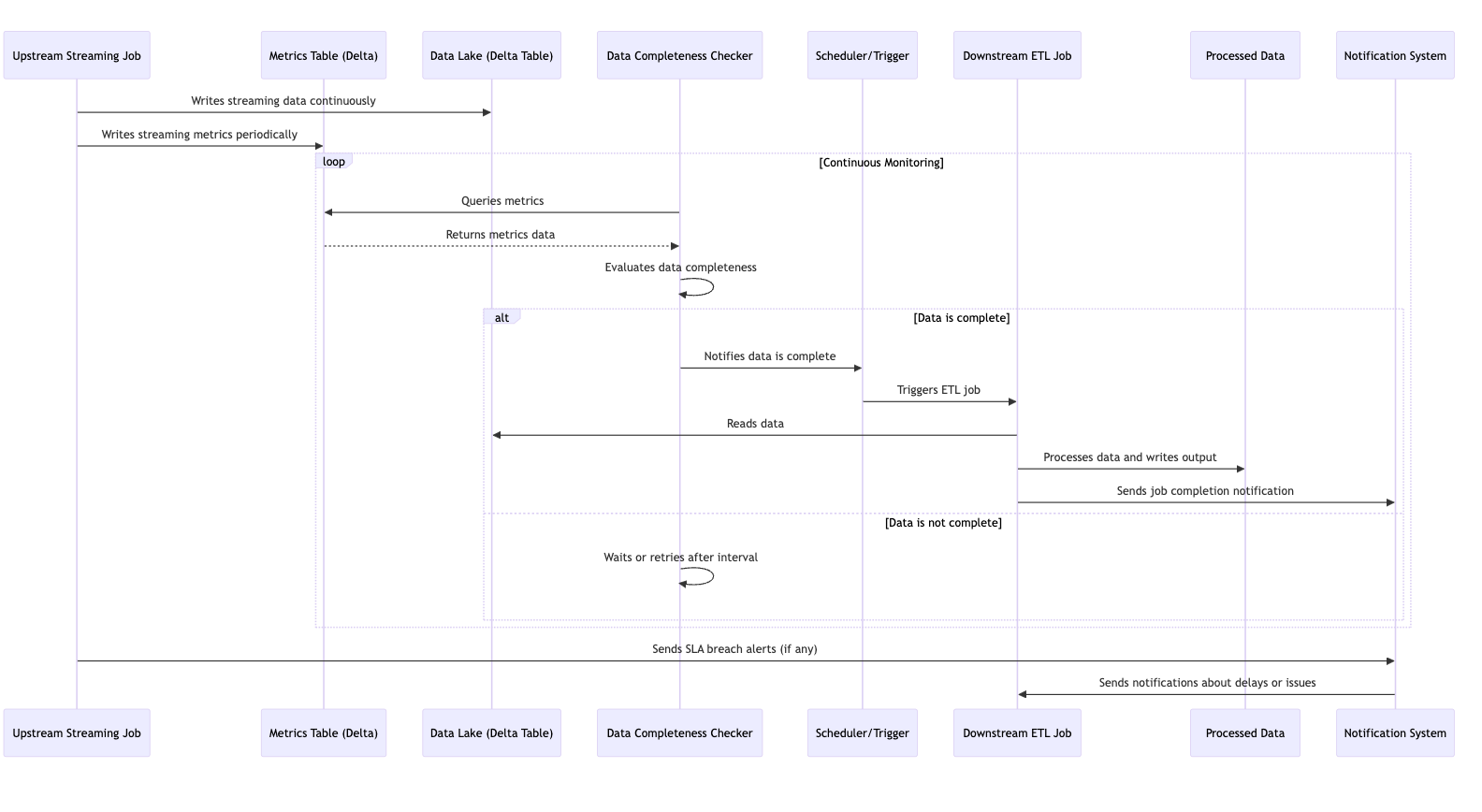
Choosing the Right Method
The optimal strategy depends on several factors:
Data Freshness Requirements: Methods involving real-time monitoring and triggering are preferred for use cases requiring near real-time data.
Data Accuracy Criticality: Mission-critical applications, like financial reporting, require robust checks to ensure data completeness.
Team Capabilities: The technical expertise of your team may influence the feasibility of implementing more complex solutions.
Infrastructure: Existing tools and platforms (e.g., Databricks, dbt, Airflow) may guide the choice of method.
Communication and Coordination: The level of collaboration between upstream and downstream teams affects the suitability of particular approaches.
Final Thoughts
By carefully considering these strategies, you can design a data pipeline that ensures timely and accurate data processing, aligning with technical capabilities and business needs. It's essential to involve all stakeholders in decision-making to agree on SLAs, data quality expectations, and operational responsibilities.
Keep This Post Discoverable: Your Engagement Counts!
Your engagement with this blog post is crucial! Without claps, comments, or shares, this valuable content might become lost in the vast sea of online information. Search engines like Google rely on user engagement to determine the relevance and importance of web pages. If you found this information helpful, please take a moment to clap, comment, or share. Your action not only helps others discover this content but also ensures that you’ll be able to find it again in the future when you need it. Don’t let this resource disappear from search results — show your support and help keep quality content accessible!